Operationalizing AI Governance: Translating NIST AI RMF into Reference Architecture
Bhaskar Boruah
An architectural interpretation of NIST AI RMF 1.0 and practical platform patterns for Govern, Map, Measure, and Manage.
This article presents an architectural interpretation of NIST AI RMF 1.0 and proposes implementation patterns for operationalizing its outcomes. It is not an official NIST reference architecture.
AI RMF is not a compliance checklist. It is an operational architecture requirement that must be wired into platform design, delivery, and runtime control.
In this article, you will learn:
- how RMF translates into practical platform functions,
- why Govern, Map, Measure, and Manage must be treated as distinct implementation domains,
- and how a reference architecture for a RAG assistant closes the loop.
When most teams first pick up NIST AI RMF 1.0, they treat it like a compliance checkbox. Legal or GRC reads the document, creates a policy deck, and throws it over the wall to engineering with “please implement.” Months later, they have an attestation, a nice binder, and zero change in production behavior.
That is the failure mode I want to address.
The AI Risk Management Framework can be interpreted as a set of operational outcomes that platform architecture must enable. The four core functions—Govern, Map, Measure, and Manage—describe technical properties that an AI platform either has or does not have. You satisfy them with components, pipelines, and a real-time control plane, not with a memo.
This post is for the people who actually build the platform: AI architects, ML platform leads, staff engineers, and the rare CISO who reads diagrams. I’m going to walk through what each function looks like as a system, not as a policy, and finish with a worked example.
The reframe: RMF is a set of system requirements
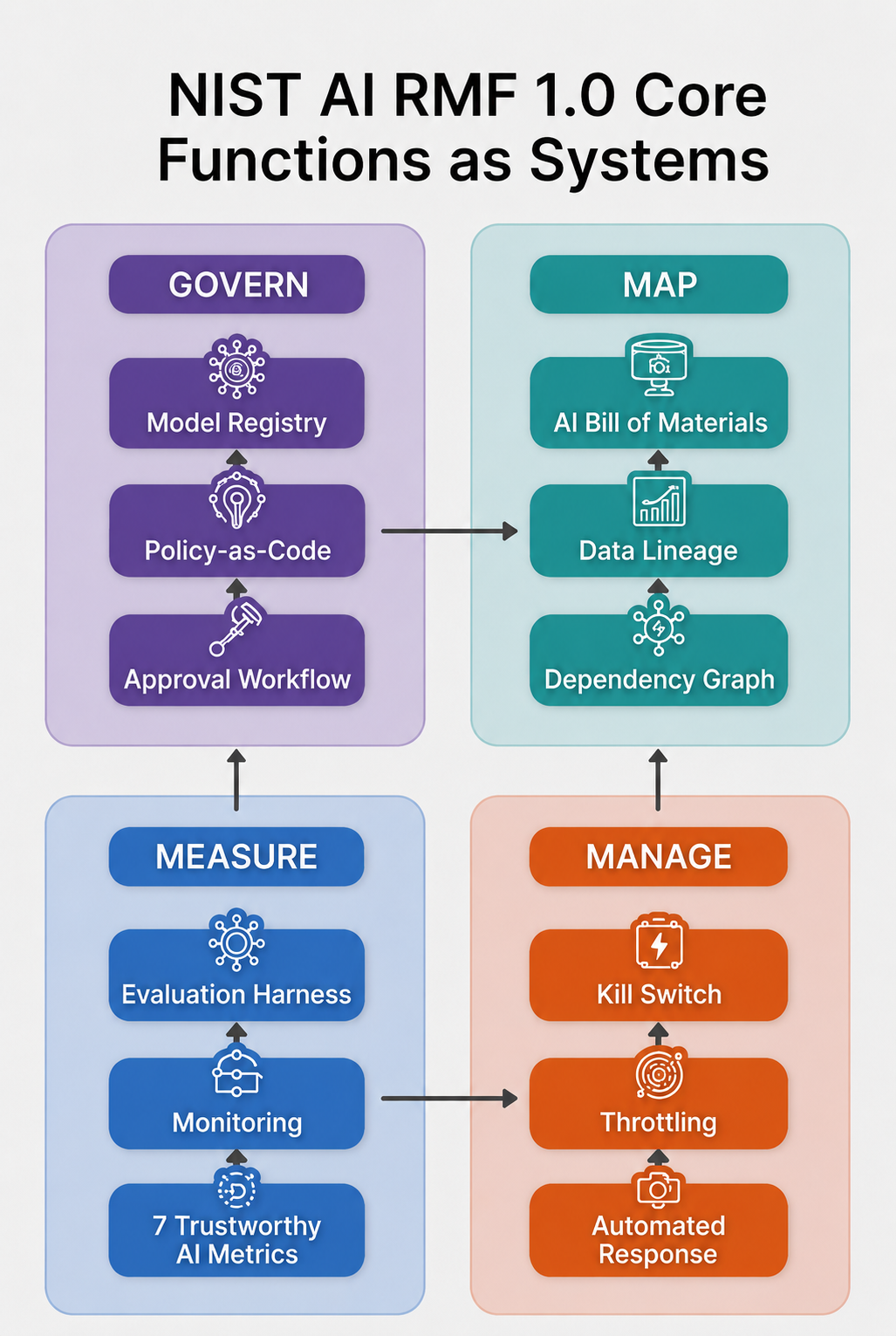
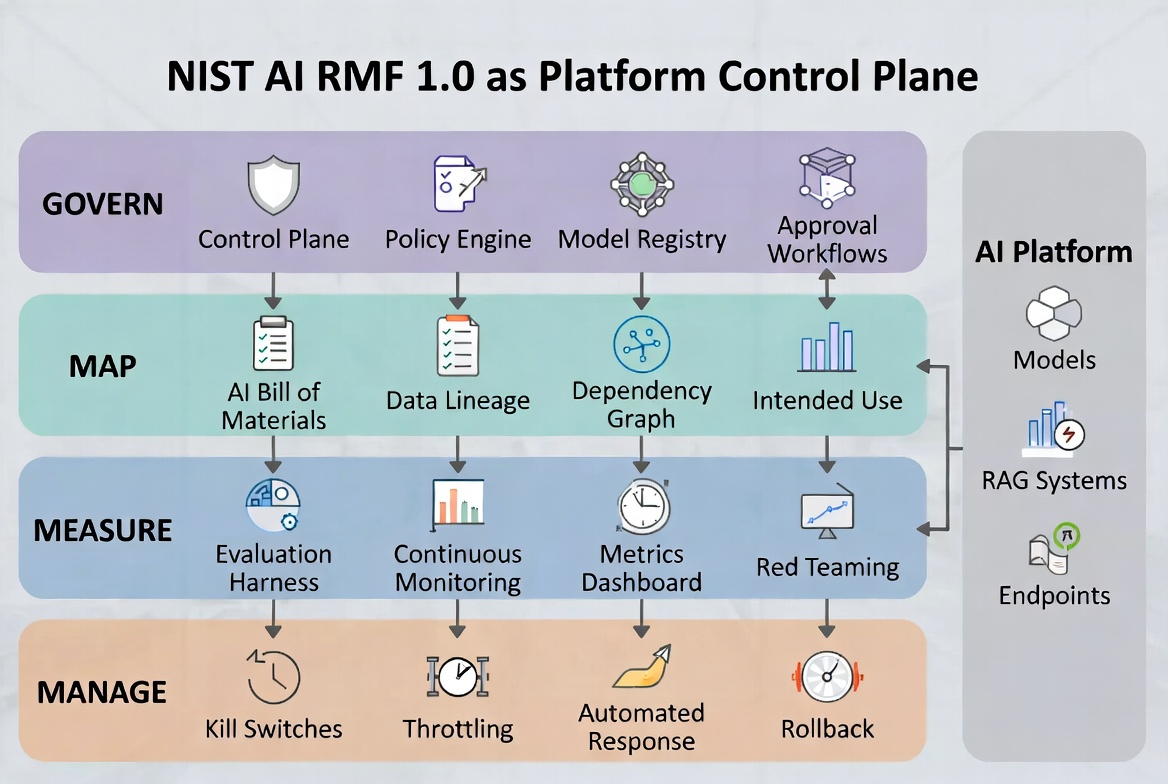
Read AI RMF 1.0 with an architect’s eye and the four functions can be translated into platform capabilities and operating controls:
- Govern isn’t “have policies.” It’s: you can prove who approved every model in production, what they approved it for, and when that approval expires.
- Map isn’t “document intended use.” It’s: for any model in production, you can answer in under a minute what data it was trained on, who the stakeholders are, what failure modes have been considered, and what it is authorized to do.
- Measure isn’t “test for bias.” It’s: every model emits a continuous stream of measurements across the seven trustworthy AI characteristics, and those measurements are wired to alerts and gates.
- Manage isn’t “respond to incidents.” It’s: there is a code path that disables, throttles, or rolls back any model in production within a defined SLA, triggered automatically by Measure.
Once you read it this way, the gap between most production AI platforms and what RMF actually requires becomes uncomfortable. The good news is that the gap is buildable.
Govern: the control plane
Govern lives at the platform layer. It is policy-as-code, approval workflows, and a model registry that knows more than just artifacts and versions.
One implementation pattern that supports these outcomes includes:
- A model registry that is also a policy engine. Models do not just have versions and metadata. They have approval states tied to specific use cases, risk tiers, and expiration dates. A model approved for “internal employee summarization” cannot be invoked by a customer-facing endpoint, full stop, enforced at the SDK or gateway layer.
- Policy-as-code for AI use cases. OPA/Rego, Cedar, or a custom DSL—the rule is the same: “Can system X use model Y for purpose Z?” should be a programmatic decision, not a Slack thread.
- Decision logs. Every approval, exception, and override is logged with the human in the loop. This is what makes RMF audits survivable.
- Agent identity management. When an autonomous agent acts on behalf of a user, Govern means checking the scope and identity of the agent programmatically at the gateway, just like a human user.
The mistake teams make is putting Govern in Confluence. If your governance lives in documents, it does not live in production.
Map: the AI bill of materials
Map is about context—what the system is, where it sits, what depends on it, and what it depends on. It is the function most often shortchanged because it feels like documentation, and engineers hate documentation.
The reframe: Map is the AI BOM (bill of materials) plus a machine-readable intended-use contract.
The components:
- System inventory. Every model, every deployment, every endpoint. Sound obvious, but at most organizations of any size, no one can produce this list reliably. If you can’t, this is where you start.
- Data lineage. For each model: training data sources, preprocessing steps, evaluation data, fine-tuning data. This is what lets you answer, “Is this model affected by the X incident?” in minutes rather than weeks.
- Intended-use specs. Structured, machine-readable. What is this model for, what is it not for, who are the affected populations, and what are the known failure modes. This is the document that gets read every time someone proposes a new use case.
- Dependency graphs. Which products depend on which models; which models depend on which datasets and third-party APIs. If a foundation model provider deprecates a version, you need to know your blast radius in seconds.
Map is also where third-party and supply-chain risk surfaces most starkly. NIST’s recent guidance puts more weight on supply-chain integrity, and most teams cannot today produce a clean answer to “What foundation models are in our stack and what is our exposure if any of them changes?”
Measure: the evaluation infrastructure
Measure is the function where architects can deliver the most leverage and where the work is most underspecified. The framework lists seven trustworthy AI characteristics—valid and reliable; safe; secure and resilient; accountable and transparent; explainable and interpretable; privacy-enhanced; fair with harmful bias managed—and notes that they trade off against each other. Your job is to operationalize them.
The architectural pieces:
- An evaluation harness as first-class infrastructure. Not a notebook. A service that runs predefined evaluation suites against any registered model on demand and on schedule, with results stored in a queryable database.
- Pre-deployment gates. No model graduates from staging without passing the evaluation suite for its risk tier. Gates are wired into CI/CD, not approved manually.
- Continuous monitoring. Drift, calibration, performance, and fairness metrics—all sampled from production traffic, treated like SRE-grade telemetry, with dashboards and alerts.
- Red-team pipelines. For higher-risk models, especially generative, you need adversarial evaluation that runs on a schedule: prompt injection, jailbreaks, harmful content elicitation, data extraction. Output is treated as a test result, not a one-off security exercise.
- Human-in-the-loop sampling. Some characteristics—fairness in context, harm severity, explanation quality—resist full automation. Build the infrastructure for structured human review and feed those judgments back as evaluation data.
The trap to avoid is treating Measure as “ML metrics.” Accuracy and AUC do not measure trustworthiness. Bias metrics across subgroups, calibration under distribution shift, robustness to perturbation, and leakage of training data are the things RMF wants you to measure, and most ML platforms do not instrument them by default.
Manage: the response system
Manage is where Govern, Map, and Measure pay off. It is the runtime control plane—the ability to take action on a model in production.
What this looks like as architecture:
- Per-model kill switches. Every model in production has a feature flag or routing rule that can disable it. Disable means traffic gets shed, falls back, or fails closed—defined per use case.
- Throttling and shadow modes. Often you do not want to kill; you want to reduce blast radius. Architects need the ability to route a percentage of traffic, route to a fallback model, or run a model in shadow mode (predictions logged, not served).
- Automated triggers from Measure. If your fairness metric breaches thresholds or your drift detector fires, the response should not require a human paging a different human. It should at minimum throttle and notify, with humans deciding whether to fully disable.
- AI-specific incident response. Most incident response is built for outages. AI incidents are different: a model can still be up but quietly producing biased outputs, hallucinating, or leaking training data. Your runbooks need to cover these.
- Rollback as a first-class operation. Model rollback is not the same as code rollback. The previous version’s behavior depends on its training data and config; you need to be able to revert atomically.
The most common gap I see is this: organizations have everything wired up to Govern and Map, can measure things, and then have no way to act on what they measure faster than a weekly meeting cadence. Manage is the function that closes the loop.
The Generative AI wrinkle
The Generative AI Profiles (NIST AI 600-1, July 2024) added twelve risk categories and hundreds of suggested actions to the framework. Most of them have architectural implications:
- Provenance. You need to know what a model said, what it was prompted with, what it retrieved, and what tools it called. This is a logging architecture problem, and one most teams do not solve until after an incident.
- Retrieval guardrails. RAG systems push data governance into the inference path. Permissions on documents have to be enforced at retrieval time, not assumed.
- Output filtering. Pre- and post-generation classifiers for harmful content, PII, and prompt-injection-driven exfiltration. These are services, not afterthoughts.
- Prompt and template management. Treat prompts like code: versioned, reviewed, evaluation-gated. Most production Gen AI failures race back to a prompt change no one tested.
- Confabulation budgets. For generative systems, you need to know your hallucination rate per use case, and where it sits relative to your tolerance. This is a measurement problem with an architectural answer.
If you are building anything generative, the Gen AI Profile is where you should be spending serious architectural attention this year.
Key takeaways
- RMF is a platform architecture framework, not a documentation exercise.
- Govern, Map, Measure, and Manage are operational functions, not checkbox categories.
- The most important work is wiring these functions into delivery, runtime control, and incident response.
Worked example: an internal RAG assistant
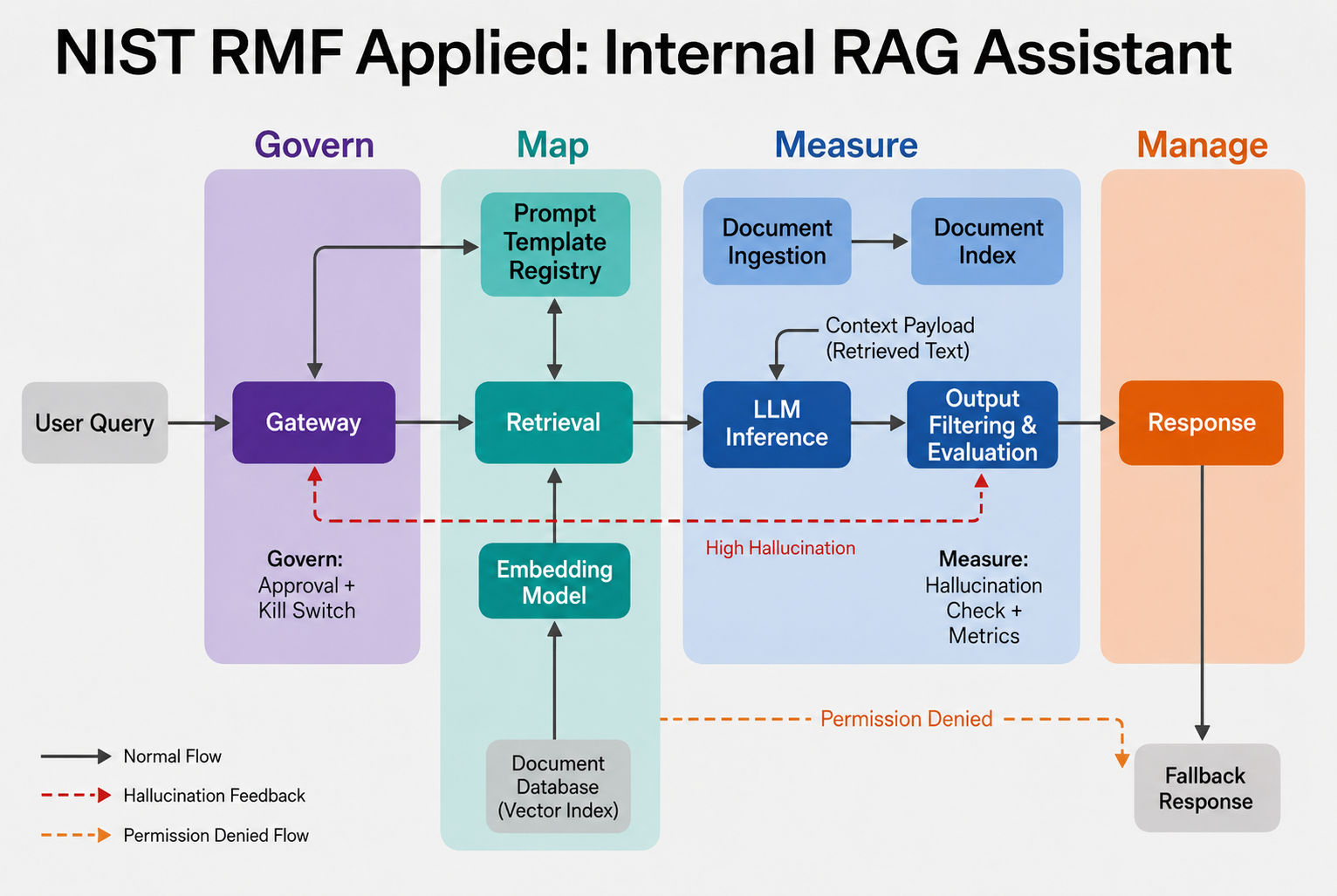
Concrete is better than abstract. Imagine you are building an internal RAG assistant—employees ask questions, the system retrieves from internal documents, and an LLM generates an answer. How does RMF show up in the architecture?
Govern. The assistant is a registered system. It is approved for “internal employee Q&A on non-confidential documents.” It cannot be invoked from customer-facing surfaces, enforced at the gateway. The foundation model behind it has its own approval, and so does the embedding model. There is an expiration date and a re-approval workflow.
Map. The system inventory shows the assistant, its endpoint, its embedding model, its LLM, and the document sources it indexes. Data lineage tracks which document repositories feed it. An intended-use spec spells out who can use it, what it should not be used for (medical, legal, HR decisions), and the known failure modes. The dependency graph flags that the LLM is a third-party API, so a vendor change triggers a review.
Measure. An evaluation suite runs on a golden set of internal questions weekly and on every prompt template change, with thresholds on accuracy, citation correctness, refusal rate, and prompt-injection resistance. Production traces are sampled for hallucination rate via a separate evaluator model and human review. Retrieval permission errors are tracked as a top-line metric.
Manage. The assistant has a kill switch at the gateway, plus per-document-source disable controls (so a leaked document can be removed from retrieval without taking down the whole system). If hallucination rate breaches threshold, the assistant automatically switches to a more conservative prompt template and notifies the on-call team.
None of this is exotic. All of it requires intent at architecture time. Try retrofitting it after launch and you will find yourself replatforming.
Where this is heading
Recent profiles and implementation guidance suggest movement toward more operational and sector-specific interpretations of AI governance. One clear direction is that the framework is shifting from voluntary, abstract guidance to operational, implementation-ready control statements. Organizations that have treated RMF as a binder are going to find themselves out of position as regulators codify it into the de facto baseline—just as we saw with the U.S. Treasury’s release of the Financial Services AI RMF profile and its 230 explicit control objectives.
The architect’s window is now. The teams that embed Govern, Map, Measure, and Manage into their platform infrastructure over the next twelve months will spend the following years harvesting the dividend: faster audits, faster incident response, faster onboarding of new models, and seamless compliance with the EU AI Act (whose high-risk requirements become legally enforceable in August 2026) and ISO/IEC 42001. The teams that do not will rebuild it under intense deadline pressure, with worse outcomes and significantly higher costs.
RMF is not a document. It is a reference architecture waiting to be built. Build it.
References
- Tabassi, E. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). NIST AI 100-1. National Institute of Standards and Technology. https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
- Autio, C., Schwartz, R., Dunietz, J., Jain, S., Stanley, M., Tabassi, E., Hall, P., and Roberts, K. (2024). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. NIST AI 600-1. National Institute of Standards and Technology. https://doi.org/10.6028/NIST.AI.600-1
- U.S. Department of the Treasury, Financial Services Sector Coordinating Council, and Cyber Risk Institute. (2026, February 19). Financial Services AI Risk Management Framework (FS AI RMF). https://cyberriskinstitute.org/the-profile/
- European Parliament and Council of the European Union. (2024). Regulation (EU) 2024/1689 — Artificial Intelligence Act. Official Journal of the European Union, 12 July 2024. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
Author’s architectural contribution
I bring a platform-first view of AI governance: how NIST AI RMF maps to runtime controls, delivery pipelines, and operational decision-making. This article translates abstract framework language into concrete architectural capabilities so engineering teams can build trustworthiness into AI systems instead of treating RMF as paperwork.
- I connect RMF’s core functions to platform services, approval workflows, evaluation infrastructure, and incident controls.
- I highlight the practical gap between policy artifacts and what production AI platforms must actually do.
- I anchor the discussion with a worked internal RAG assistant example so the architecture is immediately actionable.